About Sources
Sources connect Validio to your data systems. A source represents a single table, topic, or dataset from a data warehouse, data stream, query engine, or other supported system.
Sources connect Validio to your data systems, including data warehouses, data streams, query engines, and more. A source defines the specific dataset or table that you want to monitor and validate. Validio can validate both structured and semi-structured data.
To view your sources and source details, see Reviewing Sources. To add or manage sources, see Managing Sources.
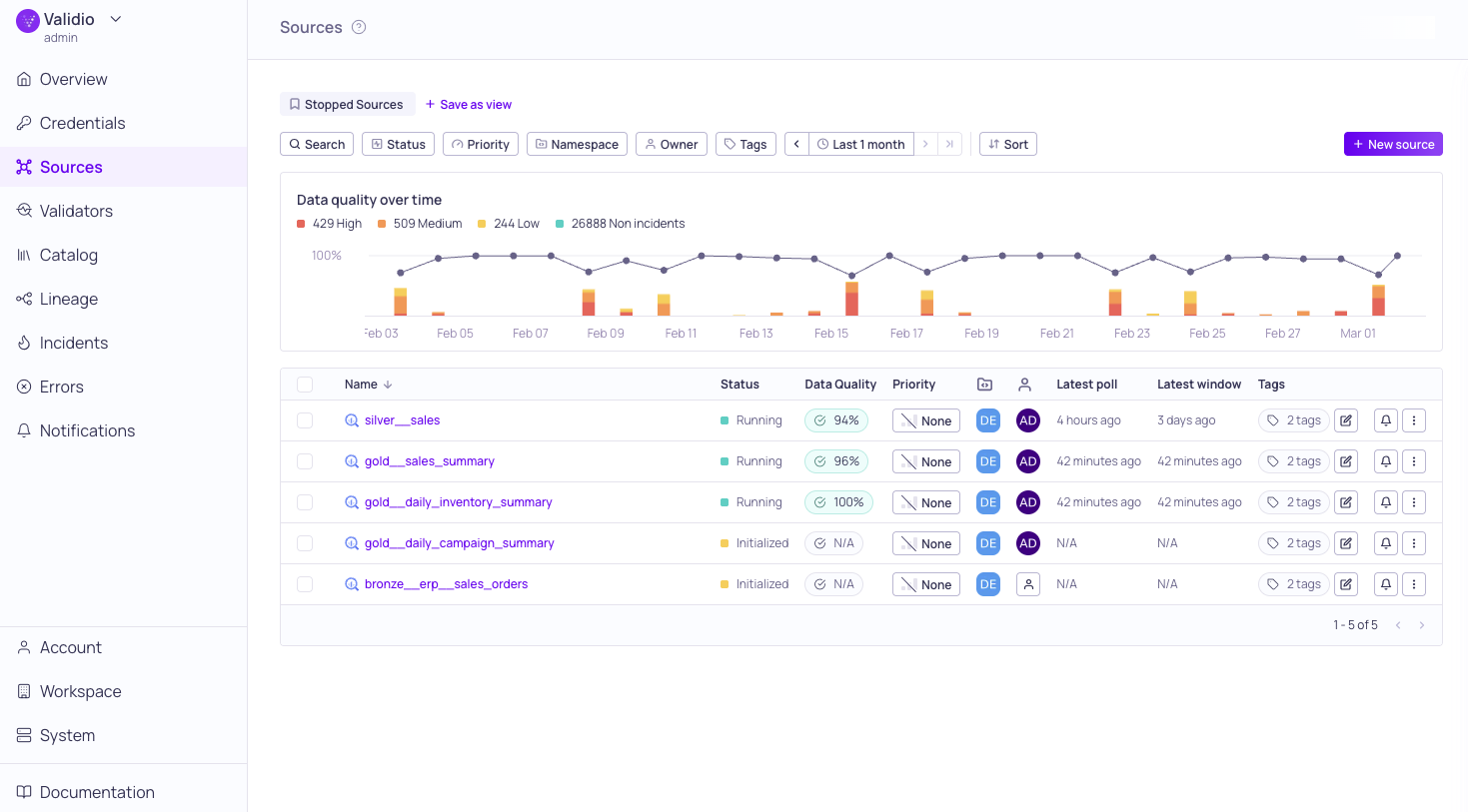
Global Sources page
Supported Data Sources
The following is a list of supported data sources. You can find instructions to connect Validio to each source on their dedicated pages.
In the Source configuration UI, supported query engine and transactional database sources are listed under Data Warehouse. For more information, see Query Engine Sources and Transactional Databases.
Configuring a Source
To add and configure a source, you need to:
- Add a credential to give Validio access to your data system. For more information, see About Credentials.
- Specify the dataset (table, topic, or custom SQL query) that you want to monitor.
- Define a polling schedule for how often Validio reads data from the source. For data streams, data is read as soon as it is available.
- Assign a priority (None, Low, Medium, High, or Critical) to indicate the importance of issues detected on the source.
Creating and updating sources requires sources:WRITE permissions. For more information, see About Validio RBAC. For step-by-step instructions, see Add a New Source. If you already have credentials configured, you can also convert discovered assets into sources from the Catalog or Lineage pages.
Schema Detection and Inference
Validio reads the schema from metadata in the source for most unstructured data types and infers the schema from existing data for most semi-structured and complex data types. Schema checks run hourly, and detected schema changes are reported as incidents.
For more information and the full list of supported data types per source, see Schema Detection.
Updated 4 months ago