About Validio
Validio uses AI agents and ML-based anomaly detection to monitor and validate data across warehouses, streams, lakes, query engines, and BI tools.
Validio uses AI agents and ML-based anomaly detection to monitor and validate data and metadata across warehouses, streams, lakes, query engines, and BI tools. It combines data observability, quality checks, lineage tracking, and cataloging in a single platform, and automates tasks that typically require manual setup and investigation.
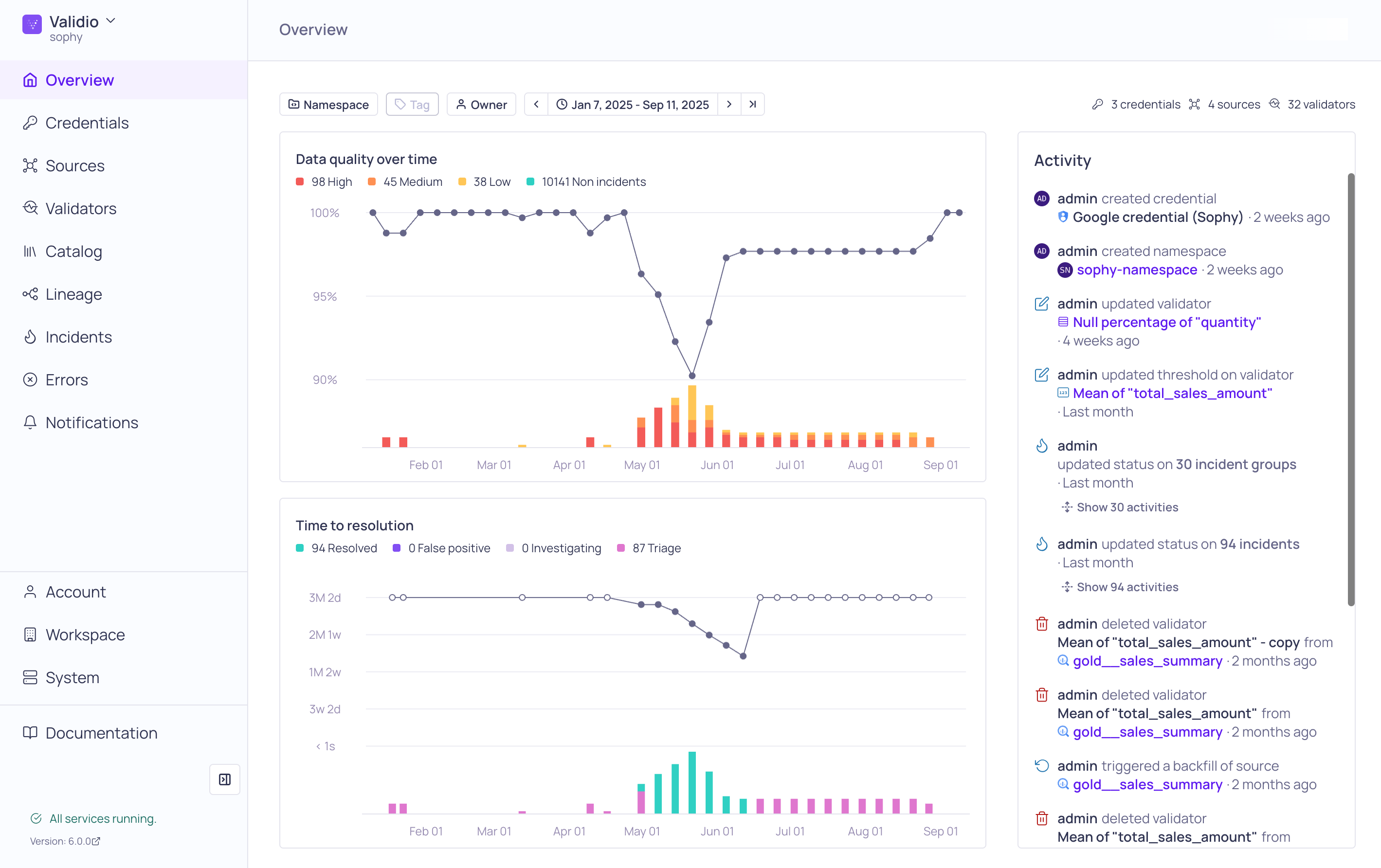
The Overview page displays a summary of your data quality, incident resolution, and recent activity.
Key Capabilities:
- Anomaly detection: ML algorithms that account for trends, patterns, and seasonality, in addition to static threshold rules. Models adapt automatically as data evolves.
- AI agents: Purpose-built agents automate monitoring setup, validator configuration, and ongoing validation — replacing manual, rule-by-rule configuration.
- Automated root-cause analysis: Lineage tracking and incident grouping identify where issues originate, so you can debug across pipelines rather than individual tables.
- Collaboration: No-code UI for business teams and a code-first interface (SDK, API, CLI) for data teams.
- Security: Supports VPC deployment and Validio-hosted options.
Getting Started Tutorial
If you are new to Validio, the Getting Started Tutorial walks you through how to monitor a data source, validate its data, investigate detected incidents, and configure notifications to stay on top of future issues. See Getting Started Tutorial.
Request a Demo
We provide custom demo sessions to help you understand how you can get started with Validio. Request your demo.
Installation Options
You can either install Validio in your VPC or host it with us, depending on your preferences and needs. For more information, see Customer virtual private cloud and Managed solution.
Updated 5 months ago
What’s Next
Learn key Validio concepts including sources, validators, windows, segmentation, and more.