Custom SQL Validators
Use Custom SQL Validators in Validio for bespoke data quality checks not covered by the out-of-the-box validator library.
Custom SQL Validators are the bespoke option for data quality checks where the metric itself isn't expressible as one of Validio's out-of-the-box validators. Use them to calculate exponential moving averages over time, compare fields or records between tables, apply custom filters, and define any metric you can write in SQL.
When to Use a Custom SQL Validator
Most data quality rules in Validio are covered by the extensive library of out-of-the-box validators. Reach for a Custom SQL Validator when the metric calculation itself needs bespoke logic — for example:
- Bespoke metric calculations such as exponentially weighted moving averages or custom ratios.
- Cross-table comparisons where the metric is the comparison itself (for example, the percentage difference in row counts between two tables).
- Business-specific checks that encode a rule involving multiple fields or conditions.
If you only need to reshape, join, or enrich your data so an out-of-the-box validator can be applied, use a Custom SQL Source instead. See Choosing Between a SQL Source and a Custom SQL Validator for guidance.
Configuring a Custom SQL Validator
To configure a Custom SQL Validator,
- Navigate to the specific source where you want to add the validator. If you need to reshape data before validation, consider configuring a Custom SQL Source first.
- Click + New validator to start the configuration wizard.
- Under Validator Type, select Custom SQL.
- Under Metric,
- Select a Window or create a new window to specify the amount of data or time over which the validator operates.
- Select a Segmentation or create a new segmentation to break your data into separate groups for analysis.
- Define the metric calculation by writing a SQL query or describing what you want and let AI generate it. The query should return a single numeric value. See Writing the SQL Query and Generating the SQL Query.
- (Recommended) Test your SQL query and automatically fix any errors. See Query Testing and Validation and Fixing Errors .
- Check Initialize using historic data to backfill with historical data for validation.
- Under Thresholds, select the type of threshold to use to detect incidents. You can configure a Fixed threshold, Dynamic threshold, or a Difference threshold. See About Thresholds.
- Under Validator Details, enter a Name, Description, Tags, and Owner.
- Click Continue to create the Custom SQL Validator.
For examples of Custom SQL validator configurations, refer to Custom SQL Validator Recipes.
Writing the SQL Query
Write a valid SQL query in the text field. The query should define the metric calculation and return a single numeric value.
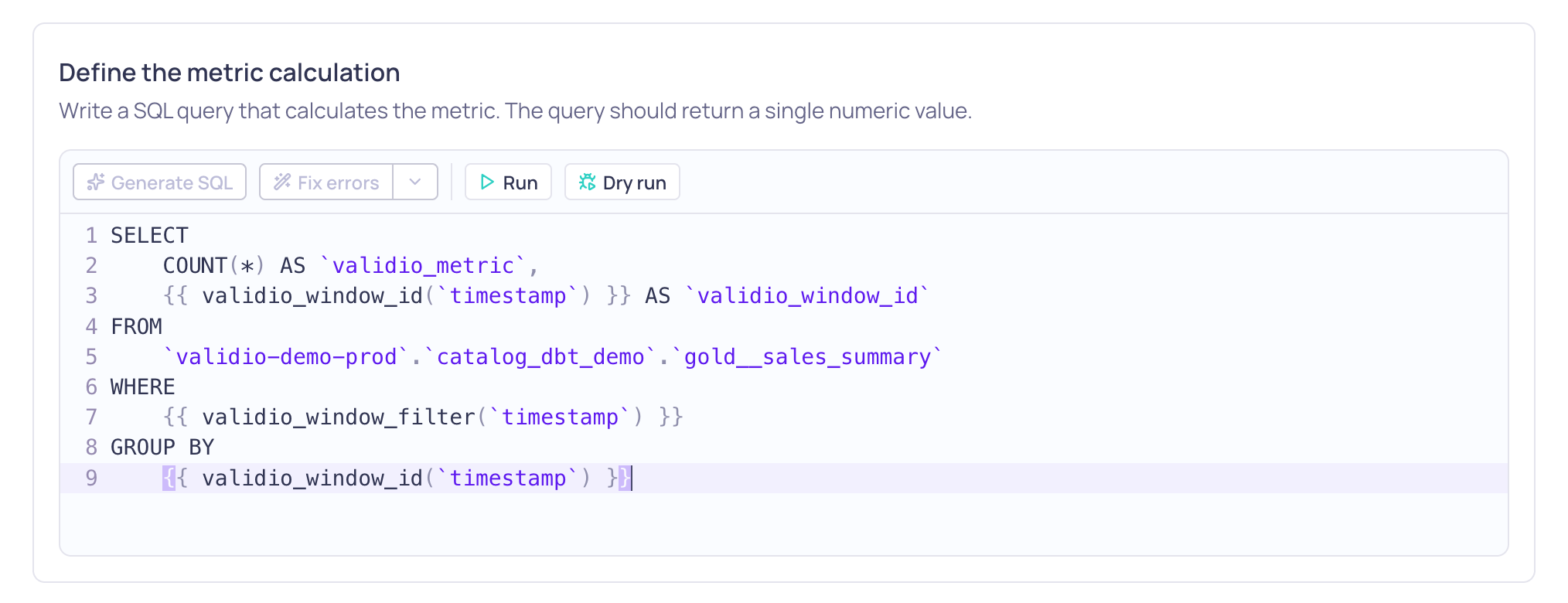
Custom SQL query field
A valid SQL query may include mandatory fields, segmentation fields, and template functions depending on the window type.
- Tumbling windows: Use template functions and return both
validio_metricandvalidio_window_id - Global windows: Use regular SQL syntax and return
validio_metric
For query syntax and examples, see Custom SQL Validator Query Syntax.
Generating the SQL Query
You will only be able to use the Generate SQL feature if your workspace settings allow LLM provider credentials and you have at least one credential configured. See LLM Credentials.
When you select Generate SQL, you can leverage AI agents to compose the SQL query for you.
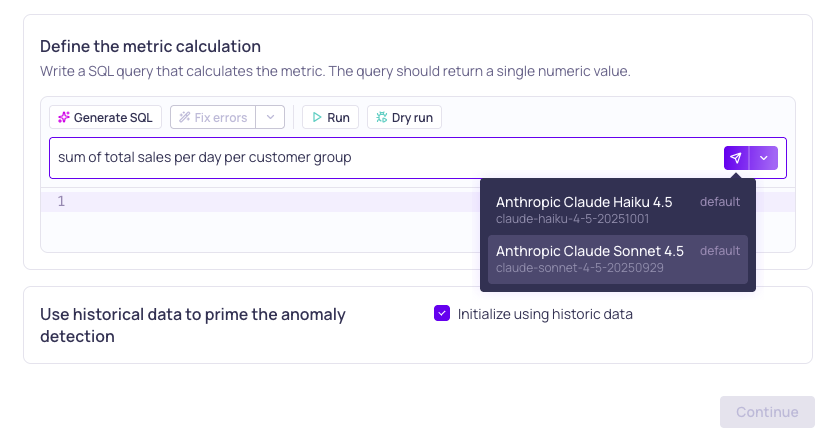
Selecting an LLM credential to generate the SQL query
- Use the text field to Describe the metric you want to calculate. Some examples of metric calculation descriptions are,
- Exponential moving average of quantity
- Sum of total sales per day per customer group
- For each city, calculate the ratio of the average total sales today against the average from two previous days. For more examples, refer to Custom SQL Validator Recipes.
- Select an LLM Credential, which is configured for a AI agent and model, to generate the SQL query for you.
Query Testing and Validation
Because syntax errors are common in custom SQL, we recommend always testing the query so that you can discover and correct errors early, instead of during source polling.
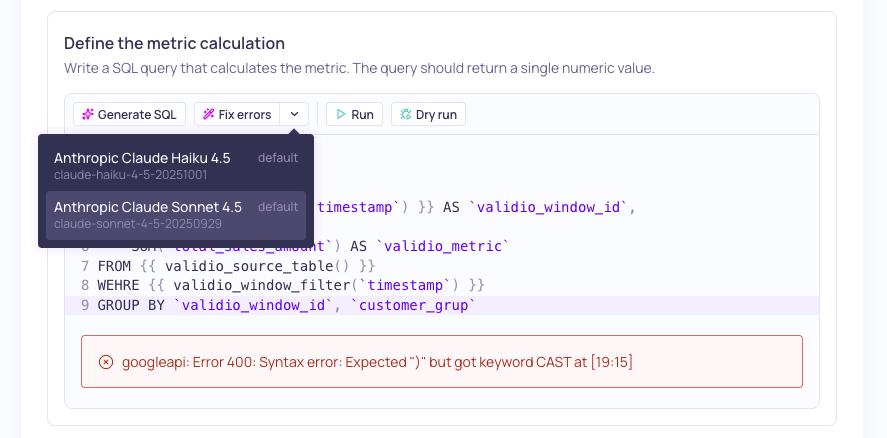
Selecting an LLM credential to fix query errors
You have two options for testing the SQL query:
- Run: (Recommended)
- If the query executes properly, returns a table with the first 20 records.
- If the query did not execute properly, returns an error message from the data source.
- Dry run: Validate the SQL query structure without running it.
Fixing Errors
You will only be able to use the Fix errors feature if your workspace settings allow LLM provider credentials and you have at least one credential configured. See LLM Credentials.
If the SQL query test fails, you can use Fix errors to analyze your query and suggest corrections.
- Click Fix errors
- Select an LLM credential to use to analyze and fix your query.
- (Recommended) Test the query again to ensure that there are no more errors.
- Click Apply to accept the changes.
Updated 22 days ago