About Validio
Validio is the Data Trust Platform built to help companies maximize their return on data and AI investments and overcome data debt—the primary reason why data and AI projects fail.
Validio combines data catalog, data lineage, and deep data observability and quality into a single platform that enables data teams and business stakeholders to jointly prioritize, validate, and improve their most business critical data assets.
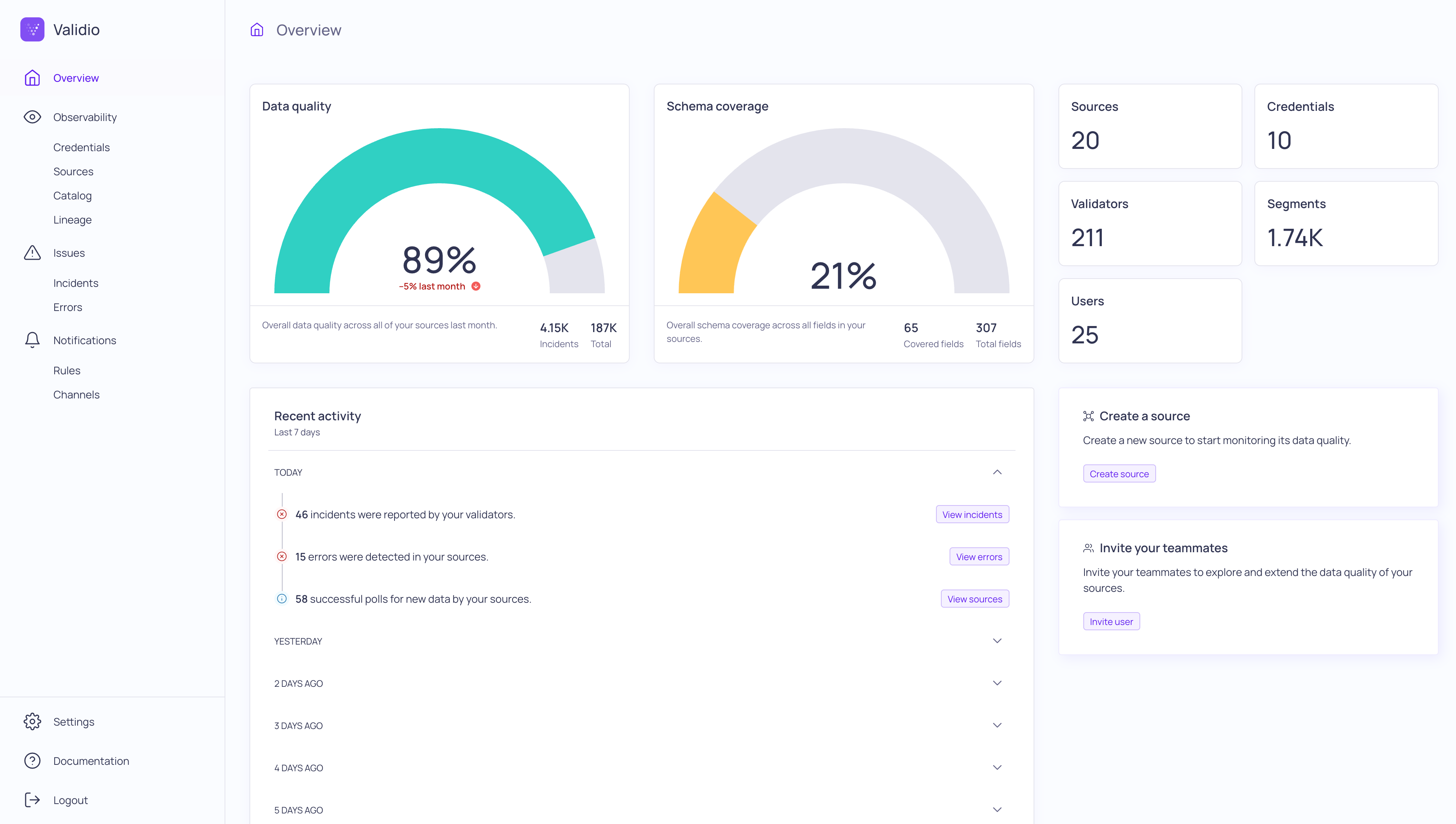
The Overview page in Validio
Validio is different from other observability platforms:
- It validates both data and metadata end-to-end for sources, from Data Streams, Data Lakes, Data Warehouses, Query Engines, and Object Stores.
- It validates data in various formats and types, not only in structured datasets but also for data in semi-structured and nested formats such as JSON blobs.
- It validates data using advanced algorithms and thresholds and recognizes patterns such as distribution shift with seasonality.
- It is built for automation-first and recommends validators based on your data sources, but also gives you the flexibility to customize and scale with the needs of your data systems.
- It is accessible through both a command line interface and a graphical user interface.
It takes five minutes to connect Validio to your data and set up your first data validation. For more information, see Getting Started with Validio.
Updated 2 months ago